

Semantic intelligence meets photogrammetry in PIX4Dmatic
In photogrammetry, the goal is to create accurate 3D models from 2D images, representing real-world environments. Semantic photogrammetry goes further by assigning meaning to objects in the scene. By labeling elements like vegetation, buildings, vehicles, and ground surfaces, it enables users to distinguish between vegetation, buildings, vehicles, and ground surfaces. Segmenting a scene to extract these categories allows for an efficient workflow in applications such as urban planning, environmental monitoring, and asset management.
The Segment Anything Model (SAM)
Enter the Segment Anything Model (SAM), a model designed to perform a wide range of segmentation tasks across a variety of images. SAM's versatility lies in its ability to separate an object from the rest of the scene with minimal input, making it a powerful tool in automated workflows such as photogrammetry pipelines.

Visual transformers and embedding
At the heart of SAM's segmentation ability is its visual transformer architecture, inspired by transformer networks in natural language processing (NLP). Unlike traditional convolutional neural networks (CNNs), which focus on local spatial relationships, visual transformers excel at understanding local and global relationships within an image, through a self-attention mechanism. The model weighs the importance of each part of an image in relation to each other. They are especially effective for complex analysis tasks like object detection and segmentation.
A central concept in SAM's ability to perform segmentation is the use of embeddings. An embedding is a compressed numerical representation of visual data that captures the key features of an image or region of an image. Instead of analyzing pixels directly, SAM converts image regions into dense vectors, where each vector encodes the most significant features of that region. This transformation allows the model to process the high-dimensional data of images in a much more manageable and computationally efficient way.
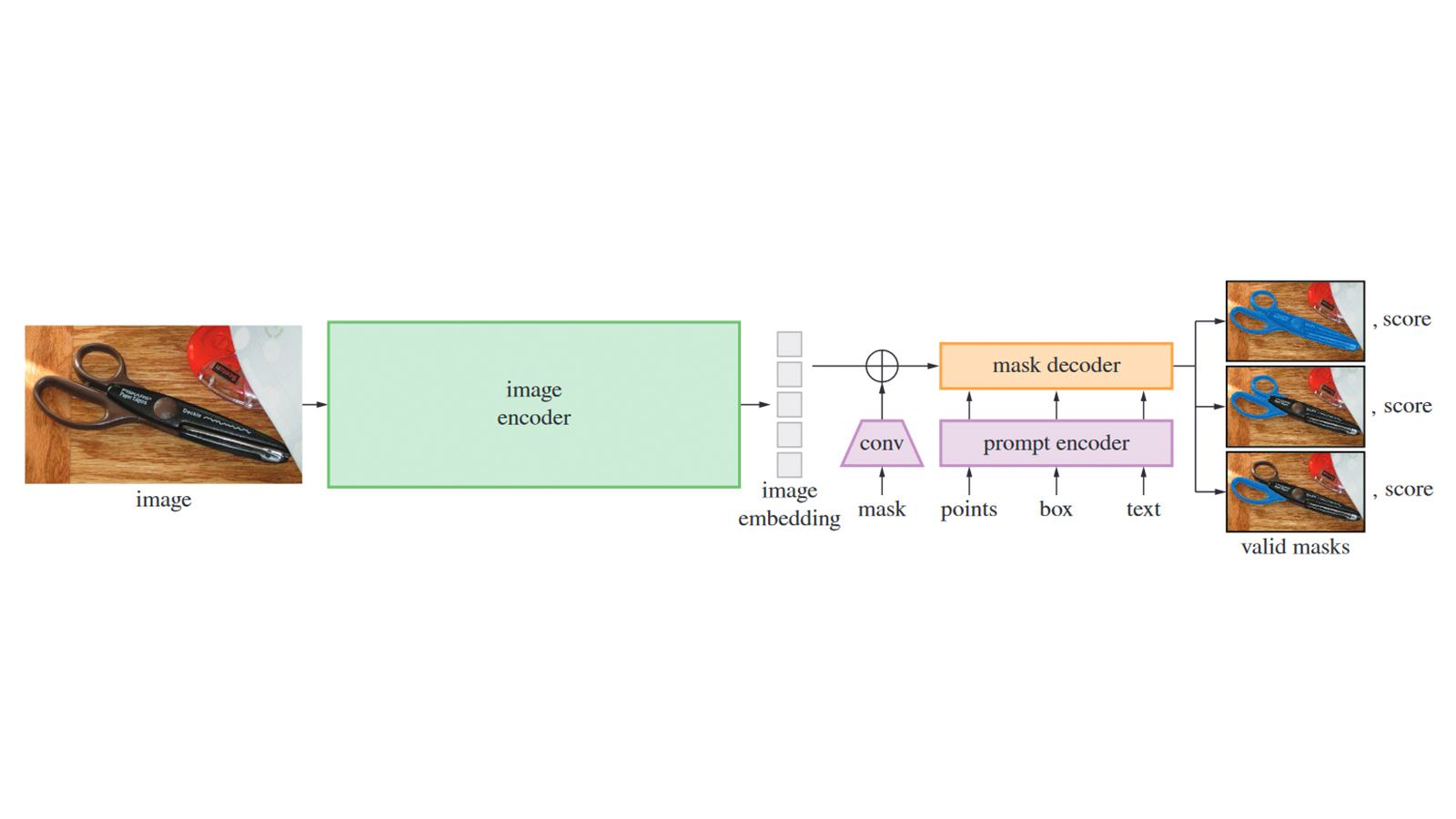
Above is a reproduction of Figure 4 from the SAM paper and a simplified architecture of the model. The process begins with the image encoder, which runs once per image to generate an embedding that captures the content in a high-dimensional space. This embedding is then passed to the interactive portion of the architecture, where the prompt encoder processes user inputs (such as points, boxes, or text), and the mask decoder uses these prompts along with the embedding to generate accurate masks. The resulting masks isolate the object of interest, enabling precise segmentation. PIX4Dmatic accepts points as user input.
Finding similarity
One way to evaluate the similarity between different embeddings is through cosine similarity, which measures the angle between two vectors in high-dimensional space, rather than their absolute distance. The core idea is that if two objects or image regions have very similar visual features, the angle between their respective embeddings will be small, and their cosine similarity will be high.
For example, suppose SAM processes two separate images of trees from different angles. If the embeddings generated from both images are very similar it is possible to infer that these are semantically equivalent objects, even though the actual pixel patterns may differ due to lighting, shadows, or perspective changes.
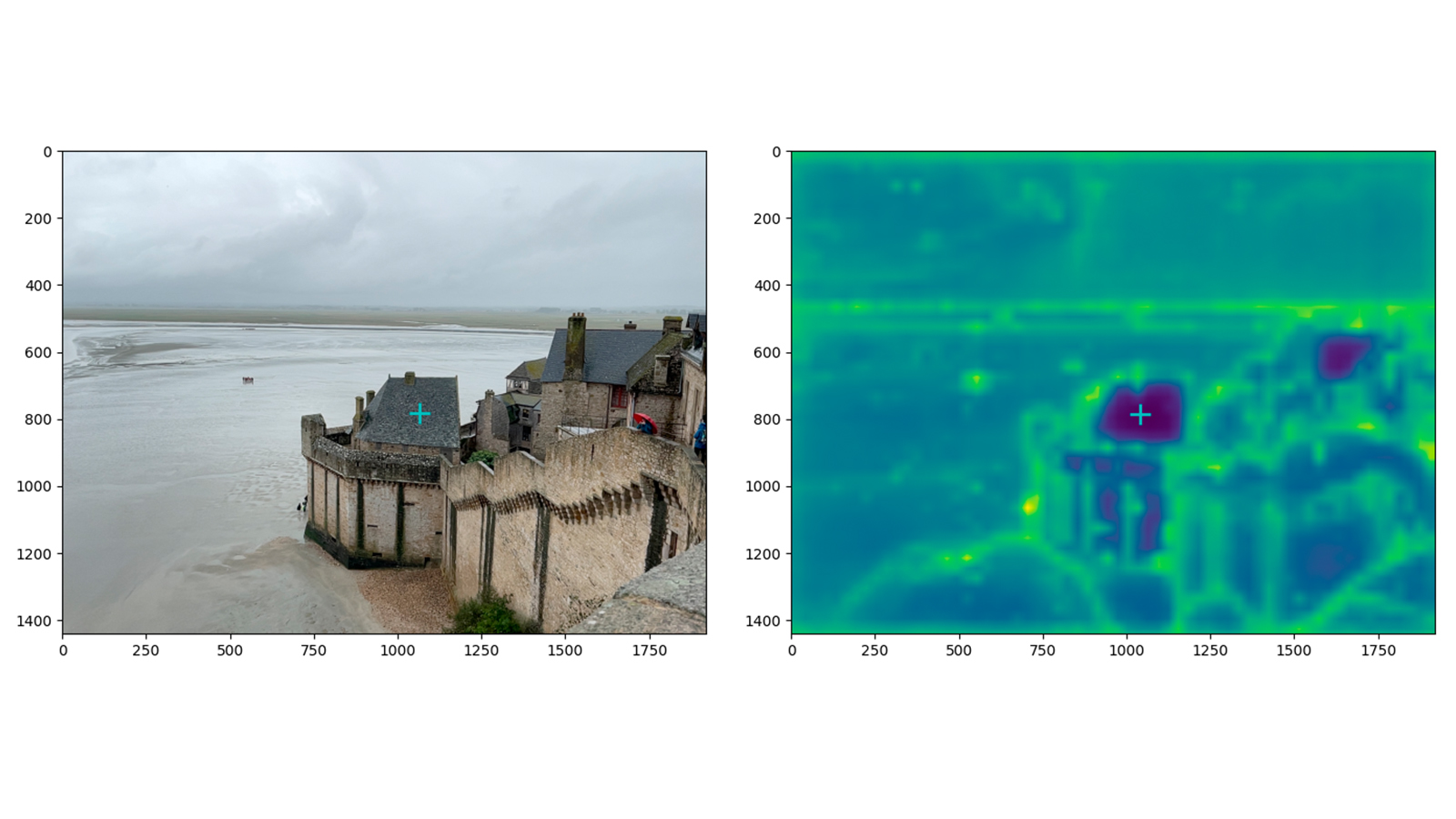
In the image above, the prompted pixel (marked by the green cross) selects a specific point in the embedding space, and the cosine similarity is calculated between the embedding of this query point and those of all other pixels in the image. The results are visualized on the right, with darker colors indicating higher similarity. The general structure of the scene is preserved, the two rooftops show particularly high similarity.
The integration of SAM in PIX4Dmatic
In PIX4Dmatic, we have integrated the Segment Anything Model to enhance our toolset with semantic awareness, it is a crucial component for future innovations in photogrammetry and its versatility opens the door to further tasks that require segmentation, object classification, or scene understanding.
Object selection powered by SAM
One of the key tools where SAM is actively employed is the Object Selection tool, allowing users to select objects directly from the 3D point cloud. Thanks to photogrammetry, we can relate 2D image information to the 3D point cloud, allowing SAM to effectively generate three-dimensional masks from 2D segmentations.
In practice, this means that once an object is selected, it can be isolated, manipulated, or processed further, such as for classification or annotation purposes. This capability is essential in workflows that require object-specific manipulation or analysis within the point cloud, providing users with a more intuitive way to interact with complex 3D data.
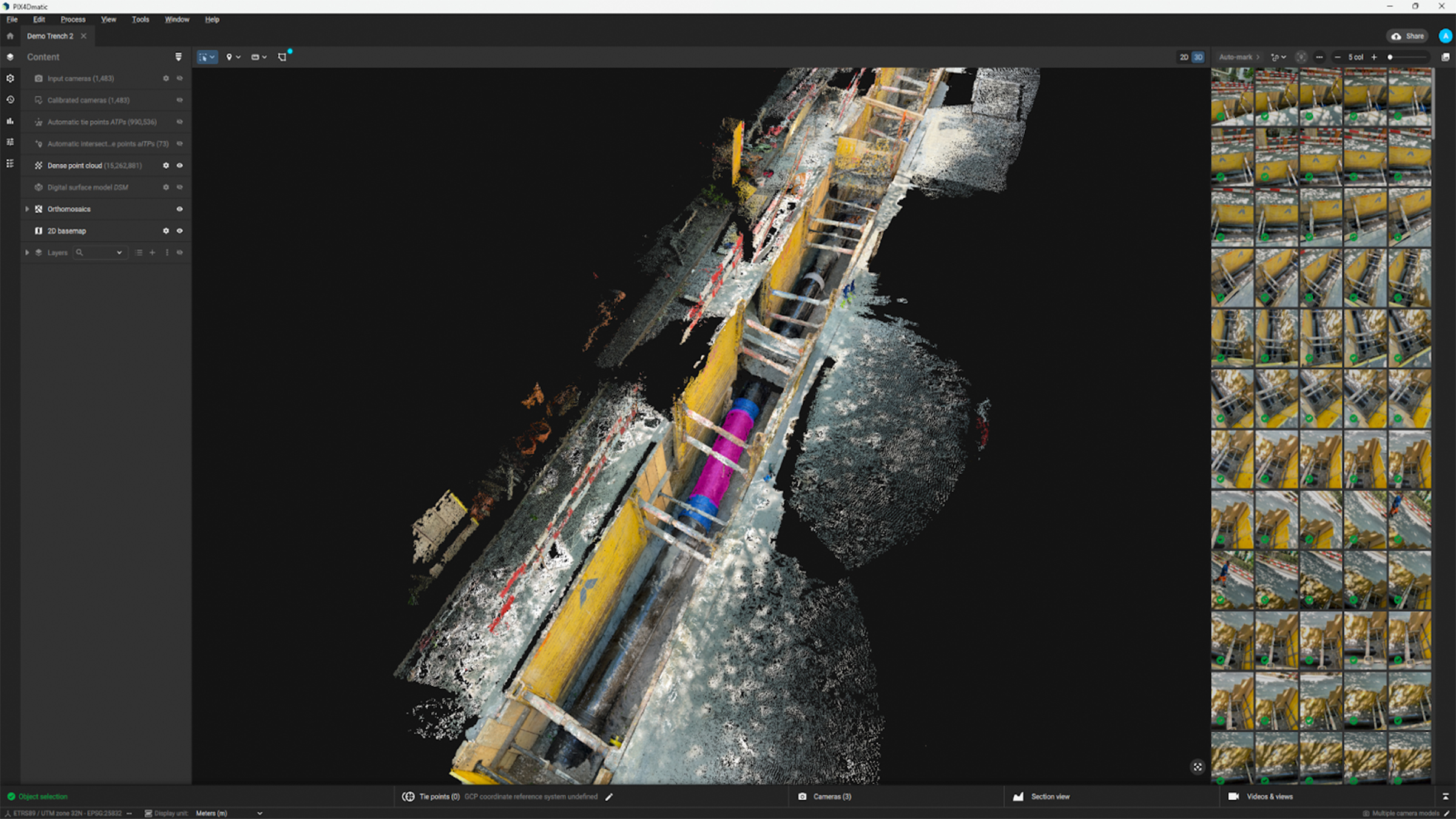
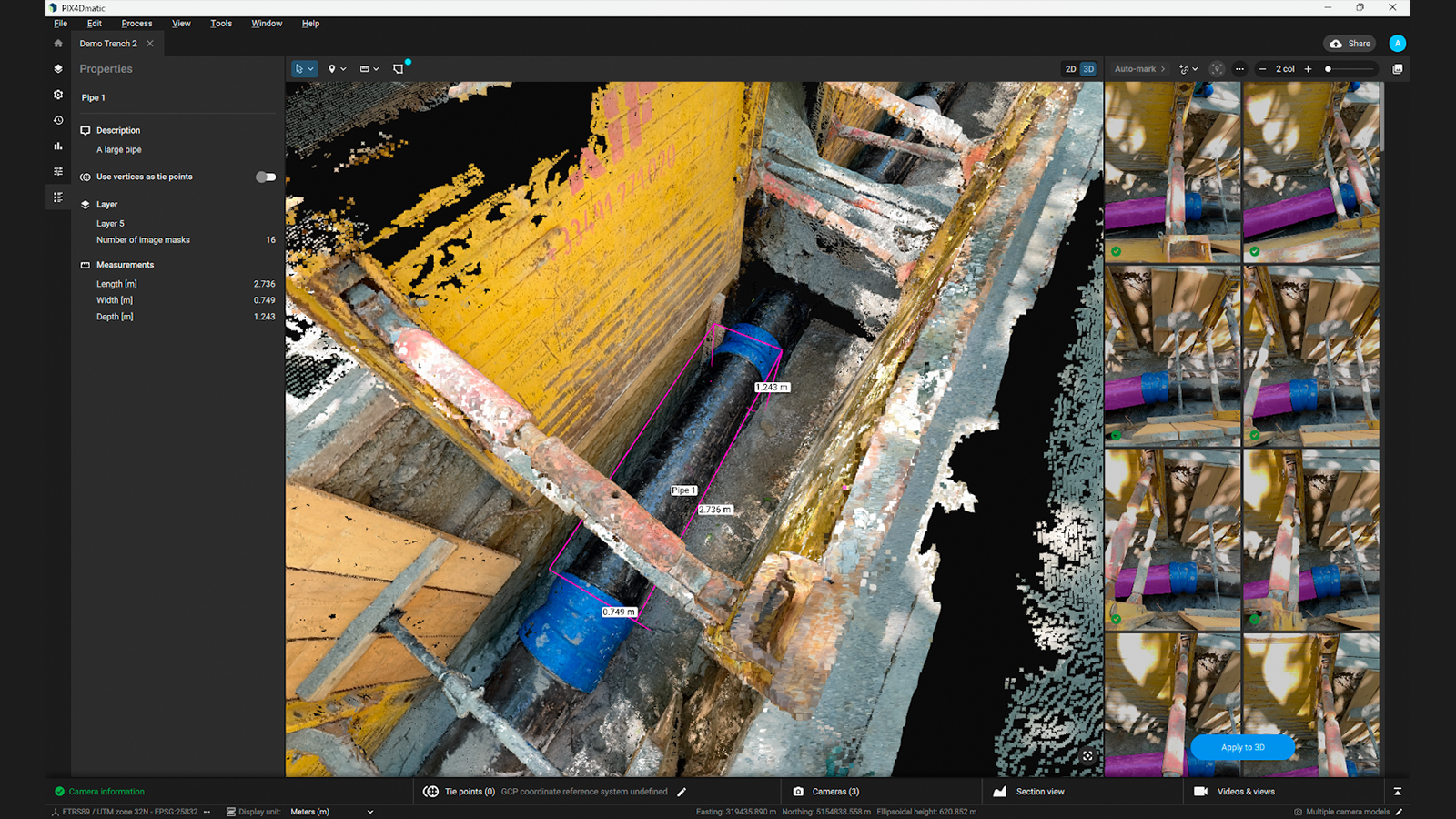
Masks workflow: full control for semantic segmentation
In addition to Object Selection, SAM powers the Masks Workflow, which allows users to directly create masks on images. This workflow gives users complete control over the segmentation process, enabling the precise masking of objects within individual images. Once created, these masks serve multiple purposes such enhancing reconstruction accuracy and facilitating object-specific processing.
How can masks in PIX4Dmatic can be utilized?
- Constraining dense and mesh creation: masks can be used to remove unwanted objects from the reconstruction. For example, if you want to exclude temporary objects (such as vehicles or equipment) from your scene, you can create masks for those objects, ensuring that they are not included in the dense point cloud or mesh
- 3D selection for point cloud classification: the masks can be transformed into 3D selections, allowing you to classify specific sections of the point cloud based on the selected masked areas. This feature is particularly useful in cases where certain objects, like vegetation or buildings, need to be classified or treated differently in post-processing
- Automatic object measurements: once masks are created, they can be used to automatically measure the dimensions of the selected object, providing users with quick and accurate geometric data for objects of interest within the scene
- Custom reporting feature: masks are also integrated into the custom reporting feature, allowing users to document interesting objects as part of their project evidence. This can be particularly useful for legal, construction, or survey documentation, where accurate documentation of specific objects is required
The future of SAM with PIX4Dmatic
The Segment Anything Model represents an important advancement in the pursuit of semantic-aware photogrammetry. It lays the groundwork for a pipeline that not only reconstructs scenes in 3D but also understands and categorizes the elements within those scenes. In the current implementation within PIX4Dmatic, SAM can already be used to perform various segmentation tasks, which facilites workflows that rely on object differentiation and classification. Looking ahead, SAM's capabilities will be expanded in future releases of PIX4Dmatic. Soon, users will be able to create automatic masks based on a few annotated examples, streamlining the segmentation process even further.


